1. Digitalni model govornog signala
1.1 Model izvor‑sustav
Već je u poglavlju 6.1 najavljeno da će se analiza procesa formiranja govornog signala ograničiti na analizu modela tipa izvor-sustav (slika 6.1‑1), čija je prijenosna funkcija sa ulaza na izlaz što sličnija stvarnoj prijenosnoj funkciji vokalnog trakta. Tim se modelom ne pokušavaju modelirati fizikalne pojave unutar samog vokalnog trakta, već isključivo obzirom na njegove krajeve. Zato se za takve modele kaže da su ekvivalentni s krajeva (engl. terminal analog model). U tu grupu modela ubraja se i model s spojenim cijevima bez gubitaka analiziran u poglavljima 6 i 7. Dakle, radi se o linearnom sustavu čiji izlaz ima željena govoru slična svojstva, kada se njime upravlja nizom parametara koji su na neki način povezani s procesom nastanka govora. Od posebnog su značaja vremenski diskretni modeli ekvivalentni s krajeva, opisani u poglavlju 7, jer je takvim modelima moguće predstavljanje otipkanih govornih signala.
Za generiranje signala sličnog govornom signalu, pobudni signal i rezonantna svojstva linearnog sustava moraju se mijenjati s vremenom. Pokazano je da je ta promjena spora, pa se stoga može pretpostaviti da će opća svojstva pobudnog signala i vokalnog trakta ostati nepromijenjena za većinu glasova kroz period od 10 do 20 ms. Dakle, može se zaključiti da se model govornog signala ekvivalentan s krajeva sastoji od vremenski sporo promjenjivog linearnog sustava koji je pobuđen signalom čija se svojstva također sporo mijenjaju od kvazi-periodičnih impulsa za zvučne glasove do slučajnog šuma za bezvučne glasove.
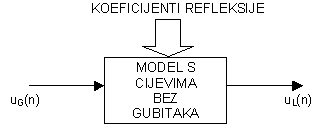
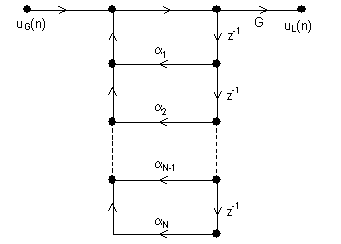
Tako npr. kod vremenski diskretnog modela sa spojenim cijevima bez gubitaka koji je prikazan na slici 8.1‑1, parametri modela su površine poprečnih presjeka segmenata cijevi, odnosno njima pripadni koeficijenti refleksije. Promjenama tih parametara kroz vrijeme modelira se vremenska zavisnost vokalnog trakta. Korištenjem vremenski diskretnog modela kakav je prikazan na slici 7.1‑3 c) moguće je odrediti odziv sustava na bilo kakvu željenu pobudu. U prethodnom poglavlju je također pokazano da je prijenosna funkcija V(z) tog modela oblika:
|
|
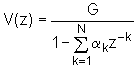
gdje parametri G i {ak} ovise o površinama poprečnih presjeka segmenata Ak uzduž vokalnog trakta (Opaska: ignorirano je kašnjenje u brojniku V(z)). Prijenosna funkcija V(z) odgovara prijenosnoj funkciji digitalnog rekurzivnog filtra koji ima samo polove. Ista željena prijenosna funkcija može se ostvariti raznim izvedbama takvog digitalnog filtra, npr.: direktna, kaskadna, paralelna ili mrežasta forma. Struktura prikazana na slici 7.1‑3 c) samo je jedna od takvih realizacija, koje su sve ekvivalentne po prijenosnoj funkciji sa ulaza na izlaz. Stoga možemo zaključiti da će što se izlaza tiče, svaki sustav s ovom prijenosnom funkcijom davati jednak izlazni signal. (Ovo nije u potpunosti točno za vremenski promjenjive sustave, ali razlike mogu biti smanjene pažljivom implementacijom.) Prema tome, vremenski diskretan model ekvivalentan s krajeva poprima opći oblik kao što je prikazano na slici 8.1‑2., a njegova stvarna 'unutarnja' izvedba može biti odabrana prema želji.
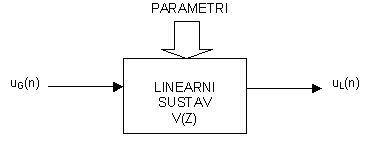
Potpuni model, osim prijenosne funkcije vokalnog trakta mora uključivati i odgovarajuću reprezentaciju promjenjive pobudne funkcije uG(n) i efekte zračenja na usnicama. U nastavku ovog poglavlja svaka komponenta modela biti će posebno proučena i zatim uključena u potpuni model.
1.2 Vokalni trakt
Rezonantne karakteristike govornog signala, ili tzv. formantne karakteristike određene su polovima prijenosne funkcije V(z), koja odgovara prijenosnoj funkciji digitalnog filtra bez nula. Takav model vokalnog trakta koji ima samo polove omogućuje vrlo dobru reprezentaciju efekata vokalnog trakta za većinu glasova. No, prema akustičkoj teoriji, prijenosne funkcije nazala i frikativa sadrže i polove i nule. Da bi se ostvarilo točno modeliranje i za te glasove potrebno je: ili stvarno dodati nulu u prijenosnu funkciju V(z), ili pak povisiti broj polova u nazivniku. Ova druga mogućnost se češće primjenjuje, jer opći oblik V(z) ostaje isti, a korištenjem većeg broja polova je do neke mjere ipak moguće modelirati nulu koja se tada nalazi između dva susjedna pola.
Kako su koeficijenti nazivnika prijenosne
funkcije V(z) u izrazu (8.1‑1) realni, korijeni polinoma u nazivniku biti će ili
realni ili u konjugirano kompleksnim parovima. Rezonantnu karakteristiku
vokalnog trakta u s-domeni možemo reprezentirati s parom
polova ![]() prema izrazu:
prema izrazu:
|
|
(8.2‑1) |
gdje su fk i 2pfk centralna frekvencija formanta u [Hz], odnosno u [rad/s]. Širina frekvencijskog pojasa rezonantne karakteristike vokalnog trakta približno je jednaka 2sk [rad/s]. Odgovarajući konjugirano kompleksni par polova u z-domeni je:
|
|
(8.2‑2) |
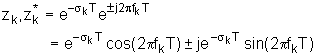
gdje je T period frekvencije otipkavanja. U z‑ravnini, udaljenost pola do ishodišta definira širinu frekvencijskog pojasa:
|
|
dok će kut pola u z‑ravnini ovisiti o fk prema izrazu:
|
|
Uz poznatu prijenosnu funkciju V(z), centralne frekvencije formanata fk i njihove širine mogu se odrediti faktorizacijom nazivnika V(z) te primjenom izraza (8.2‑3) i (8.2‑4), koji povezuju vremenski kontinuiranu i diskretnu domenu. Kao što je ilustrirano na slici 8.2‑1 a), sve vlastite frekvencije vokalnog trakta nalaze se u lijevoj poluravnini s-ravnine, budući da se radi o stabilnom sustavu. Stoga je sk>0, te vrijedi da je ½zk½< 1, tj. svi odgovarajući polovi diskretnog sustava moraju biti unutar jedinične kružnice da bi uvjet stabilnosti bio zadovoljen (slika 8.2‑1 b) ).
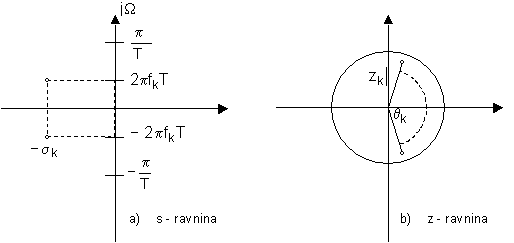
Kao što je pokazano u prethodnim poglavljima, model s cijevima bez gubitaka vodi na prijenosnu funkciju prema izrazu (8.1‑1). Može se pokazati da će svi polovi pripadne prijenosne funkcije V(z) biti unutar jedinične kružnice ako su površine poprečnih presjeka modela s cijevima bez gubitaka pozitivni brojevi. Isto tako može se pokazati da vrijedi i obrat, tj. da se svaka stabilna prijenosna funkcija V(z) oblika kao u (8.1‑1) može realizirati modelom s cijevima bez gubitaka.
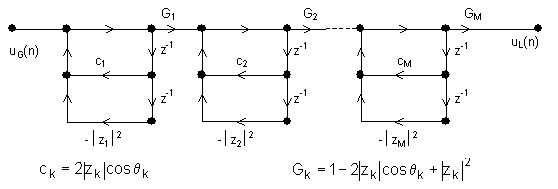
Jedan od načina implementacije prijenosne funkcije V(z) je korištenjem ljestvičaste strukture kao što je prikazano na slici 7.1‑3 c). Drugi pristup implementaciji je upotreba standardnih struktura digitalnih filtara. Može se, na primjer, koristiti direktna realizacija prijenosne funkcije V(z) kako je prikazano na slici 8.2‑2. U slučaju kaskadne izvedbe, prijenosna funkcija V(z) se razbija na kaskadu sustava 2. reda, tj.:
|
|
(8.2‑5) |
gdje je M prvi cijeli broj veći
od N/2, a
prijenosna funkcija jedne kaskade Vk(z) je:
|
|
(8.2‑6) |

Brojnik funkcije Vk(z) odabran je tako da produkt kaskada ima isto ukupno pojačanje kao i polazna prijenosna funkcija. U slučaju kada je sustav pobuđen signalom frekvencije 0, (z=1), prijenosna funkcija k‑te kaskade na toj frekvenciji iznosi Vk(z)=1. Kaskadna realizacija modela prikazana je na slici 8.2‑3.
Postoji još jedan način realizacije V(z), a to je rastavljanje V(z) na parcijalne razlomke na osnovu kojih se izvodi paralelna realizacija modela.
1.3 Zračenje na usnicama
Do sada je razmatrana prijenosna funkcija V(z) koja povezuje brzinu protoka volumena zraka na ulazu vokalnog trakta i brzinu protoka na usnicama. Obzirom da je ljudsko uho osjetljivo na promjenu tlaka, a ne na brzinu protoka, trebalo bi prikazati odnos brzine protoka volumena zraka na ulazu vokalnog trakta i tlaka na usnicama. U tom slučaju nužno je uzeti u obzir utjecaj zračenja na usnicama. Za slučaj analognog modela, odnos tlaka i brzine protoka u frekvencijskoj domeni dan je izrazom:
|
|
(8.3‑1) |
gdje je ZL impedancija
zračenja. Željeni izraz u z-domeni trebao bi imati sličan oblik:
|
|
(8.3‑2) |
U poglavlju 5.4 analiziran je utjecaj zračenja na usnicama za analogni model, te je pokazano su tlak i brzina protoka na usnicama vezani operacijom visoko-propusne filtracije, tj. niske frekvencije su potisnute. Zapravo se može reći da je niskim frekvencijama tlak približno jednak derivaciji brzine protoka volumena zraka. Stoga, da bi se odredio vremenski diskretni model ovog odnosa na usnicama treba upotrijebiti metodu diskretizacije koja izbjegava pojavu aliasinga. Poznato je da transformacija primjenom metode jednakih impulsnih odziva nije primjenjiva za visoko‑propusne filtre. Ako bi se međutim primijenio postupak bilinearne transformacije, može se pokazati da se zadovoljavajuća aproksimacija efekta zračenja na usnicama ostvaruje prvom diferencijom:
|
|
(8.3‑3) |
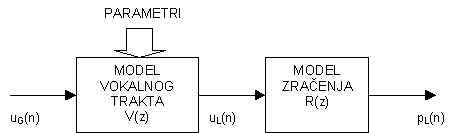
Utjecaj zračenja na usnicama uzima se u obzir slaganjem u kaskadu postojećeg modela vokalnog trakta i modela zračenja, kao na slici 8.3‑1.
1.4 Pobudni signal
Da bi se upotpunio digitalni model formiranja govornog signala, potrebno je razmotriti i način generiranja pobudnog signala za sustav vokalnog trakta s dodanim modelom zračenja na usnicama. U poglavlju 5.5 diskutirano je da se većina govornih glasova može se podijeliti na zvučne i bezvučne glasove. Grubo rečeno, za generiranje zvučnog glasa, na ulaz vokalnog trakta treba dovesti kvazi-periodične impulse, dok se za bezvučni glas kao izvor signala koristi slučajni šum.
Tipični valni oblik pobudnog signala za zvučne glasove prikazan je na slici 5.5‑6 a). Pobudni signal se sastoji od niza pulseva na pravilnom razmaku, a ti se pulsevi nazivaju glotalnim pulsevima. Uobičajeni način generiranja zvučnog pobudnog signala prikazan je na slici 8.4‑1. Generator jediničnih impulsa daje na svom izlazu niz jediničnih impulsa u pravilnom razmaku koji odgovaraju periodu osnovne frekvencije titranja glasnica (engl. pitch period). Ovaj signal pobuđuje linearni sustav čiji impulsni odziv g(n) odgovara otipkanom valnom obliku glotalnog pulsa. Pojačanje na izlazu, Av, određuje intenzitet zvučne pobude.
Sam oblik funkcije g(n) i nije tako kritičan tako dugo dok njegova Fourierova transformacija ima željena svojstva, tj. ima oblik prijenosne funkcije niskopropusnog filtra. Tako je pokazano da prirodni glotalni puls može biti zamijenjen umjetno generiranim signalom oblika:
|
|
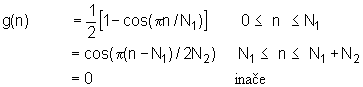

Impulsni odziv modela glotalnog pulsa g(n) prema izrazu (8.4‑1) i njegova frekvencijska karakteristika, G(ejW) prikazane su na slici 8.4‑2, za tipične vrijednosti N1=40 i N2=20. Ovakav sintetički pobudni signal je vrlo sličan stvarnom pobudnom signalu koji je prikazan na 5.5‑6 a). Na slici 8.4‑2 je vidljivo da frekvencijska karakteristika modela glotalnog pulsa ima željeni nisko‑propusni karakter.

Model prema izrazu (8.4‑1) odgovara vremenski diskretnom filtru s konačnim impulsnim odzivom, ili tzv. FIR filtru, pa je i njegova z-transformacija G(z) jednaka polinomu u varijabli z‑1 čiji su koeficijenti jednaki uzorcima g(n). Takav G(z) ima samo nule (nema polove), a već je kod izvoda prijenosne funkcije vokalnog trakta V(z) diskutirano da je all‑pole model interesantniji. Pokazalo se da se frekvencijska karakteristika slična onoj prikazanoj na slici 8.4‑2 može ostvariti i IIR filtrom drugog reda koji ima samo polove.
Model pobudnog signala za bezvučni glas je jednostavniji. Potreban je samo izvor šuma te pojačanje na izlazu za kontrolu intenziteta bezvučne pobude. Za diskretne sustave se kao generator šuma koristi generator slučajnih brojeva. Funkcija gustoće razdiobe generatora slučajnih brojeva neće biti od presudnog značaja na kvalitetu sintetiziranog govora.
1.5 Potpuni digitalni model
Spajanjem svih prethodno opisanih dijelova u jednu cjelinu dobiva se potpuni digitalni model formiranja govornog signala (slika 8.5‑1).
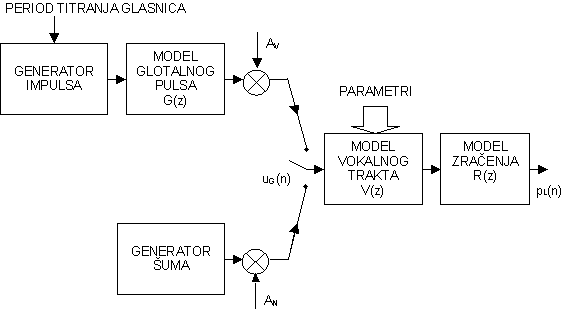
Promjena pobudnog signala postiže se preklapanjem sklopke za odabir pobude između generatora zvučnog i bezvučnog signala.
U nekim slučajevima se model glotalnog pulsa i model zračenja spajaju u jedan sustav. Kasnije će biti pokazano da se u slučaju analize govornog signala postupkom linearne predikcije, model glotalnog pulsa, model zračenja i model vokalnog trakta udružuju u jedan sustav, te su predstavljeni jedinstvenom prijenosnom funkcijom bez nula:
|
|
(8.5‑1) |
Dakle, slika 8.5‑1 je samo jedan općenit prikaz koji je moguće na razne načine modificirati.
Pitanje koje se samo po sebi nameće tiče se ograničenja ovakvog modela. Sigurno je da je konačni model daleko od parcijalnih diferencijalnih jednadžbi od kojih se krenulo, ali na sreću ni jedno od zanemarenja ne utječe bitno na primjenjivost ovog modela.
Što se tiče utjecaja vremenske varijabilnosti parametara, u kontinuiranim glasovima kao što su samoglasnici (vokali), parametri se mijenjaju vrlo sporo i model doista dobro opisuje stvarni proces. Kod tranzijentnih glasova model nije toliko dobar, ali još uvijek zadovoljava. Kod kreiranja modela krenulo se od pretpostavke kvazi‑stacionarnosti govornog signala, tj. pretpostavke da ako se govor promatra u dovoljno kratkim vremenskim odsječcima (između 10 i 20 ms), da će tada spektralna i statistička svojstva signala unutar cijelog intervala biti stalna, tj. da su parametri modela konstantni za takve vremenske periode. Tada prijenosna funkcija V(z) zaista opisuje ponašanje govornog sustava čiji se parametri mijenjaju vrlo sporo s vremenom.
Drugo ograničenje modela je nedostatak nula potrebnih za reprezentaciju nazala i frikativa. Ovo ograničenje više utječe na nazale, ali se može riješiti dodavanjem nula u model. Treće ograničenje se odnosi na zvučne frikative kod kojih jednostavni model preklapanja pobude zvučna/bezvučna nije dovoljan, jer pobudni signal za te glasove ima istovremeno i periodični i šumovit karakter. Jednostavno zbrajanje ove dvije pobude također nije dovoljno jer do pojave turbulencija i šumovitog zvuka dolazi samo u vrhovima periodičnog pobudnog signala. Zato je razvijen složeniji model koji se može upotrijebiti kada je to potrebno. Zadnje ograničenje ovog jednostavnog modela je u činjenici da period titranja glasnica mora biti cjelobrojni višekratnik perioda frekvencije otipkavanja (cijeli broj uzoraka kašnjenja), ali postoje i složeniji modeli kod kojih je i to ograničenje moguće eliminirati
1.6 Zaključak
U poglavljima 4,6,7 i 8 naglasak je bio na slijedećim temama: fizikalne osnove procesa formiranja govora, te vremenski kontinuirani i vremenski diskretni modeli za oponašanje ovog procesa. Poznavanje osnova akustičke teorije je nužno, da bi bilo moguće razumijevanje modela koji iz nje slijede. Diskutirane teme trebale bi dati uvid u osnovne karakteristike govornog signala, kao i temeljne modele koji se mogu koristiti prilikom njegove digitalne obrade.
Modeli predloženi u poglavljima 7 i 8 biti će osnova za postupke obrade govornog signala diskutirane u slijedećim poglavljima. Ove modele je moguće promatrati na dva načina: prvi se naziva postupkom analize govora, a drugi postupkom sinteze govora. U postupcima analize govornog signala težište je na algoritmima pomoću kojih je na osnovu snimljenog i otipkanog govornog signala moguće odrediti parametre diskutiranih modela na čijem se izlazu prema pretpostavci nalazi upravo taj signal. U postupcima sinteze govornog signala, model se koristi da bi se na osnovu pravilno odabranih parametara (npr. iz analize) na njegovom izlazu dobio sintetički govorni signal. Ova dva pristupa govornom modelu se često pojavljuju i istovremeno u većem broju primjena.
Uz poznavanje ovih osnovnih principa i modela, u narednim poglavljima biti će diskutirano kako je postupke digitalne obrade signala moguće primijeniti na obradu govornog signala.