2. Pregled primjena postupaka digitalne obrade govora
2.1 Kodiranje govornog signala
Uobičajeno se u laičkom razmišljanju pod pojmom kodiranja podrazumijevaju sustavi koji provode određene transformacije na signalu u svrhu njegove zaštite, tj. da nitko osim osobe koja ima pripadni dekoder nije u stanju poruku vratiti nazad u originalni oblik. Međutim pojam kodiranja govora ima u stvari drugo značenje, tj. radi se o postupku pretvorbe analognog govornog signala u digitalni oblik, koji je u današnje vrijeme mnogo podesniji kako za pohranu, tako i za prijenos. Naravno, čim je signal transformiran u digitalnu domenu, nad tim nizovima digitalnih podataka se uistinu i može primijeniti bilo kakav postupak kriptografske zaštite. Međutim uobičajen postupak kodiranja i dekodiranja govora se ne bavi problemom kriptografije, već se isključivo bavi čim učinkovitijem postupkom digitalne reprezentacije. Zbog najšire primjene, kodiranje govora predstavlja jedno od najznačajnijih područja digitalne obrade govora. U nastavku će biti ukratko nabrojani sustavi za kodiranje govora kroz njihov povijesni razvoj.
2.1.1 Prvi koderi govora temeljeni na reprezentaciji valnog oblika
Jedan od glavnih pokretača razvoja digitalne obrade govora bili su javni telekomunikacijski sustavi koji su 70-tih godina postajali sve glomazniji i složeniji. Klasični pristup temeljen na analognom prijenosu govornog signala više nije mogao zadovoljiti rastuće potrebe, pa je digitalizacija sustava telekomunikacija bila nužna. Digitalizacija je prvo provedena u telefonskim centralama (javnim i kućnim), a postepeno su i analogni telefoni zamjenjivani s digitalnim. U to vrijeme digitalizacija govornog signala bila je temeljena na reprezentaciji valnog oblika, a poznati standardi kodiranja su tzv. PCM i ADPCM, s potrebnim brzinama prijenosa od 64 kbit/s za PCM, odnosno 32 kbit/s za osnovni mod rada ADPCM kodera. Ti standardi se vode pod oznakama G.711 (PCM) i G.721, G.723, G.726, G.727 (ADPCM) i standardizirani su od međunarodnog tijela za standardizaciju telekomunikacijskog sektora ITU-T (The Telecommunication Standardization Sector of the International Telecommunication Union) Bitna značajka tih sustava kodiranja je u tome da su to algoritmi koji nastoje valni oblik govornog signala čim je moguće bolje reprezentirati i prenijeti na prijemnu stranu u svrhu vjerne reprodukcije. U tom smislu, kod tih kodera nije specijalno korištena činjenica da se radi o govornom signalu koji ima vrlo specifična svojstva, već se ti koderi kao takvi mogu koristiti i za prijenos drugih signala (npr. muzike).
2.1.2 Prvi koderi temeljeni na parametarskoj reprezentaciji govornog signala
Krajem 80-tih godina, dodatni zamah razvoju postupaka učinkovitog kodiranja govornog signala dao je razvoj mobilnih komunikacija. Kod mobilnih sustava, cijena kanala je direktno proporcionalna korištenoj brzini prijenosa, pa je zahtjev za učinkovitim sažimanjem bio od presudne važnosti. Drugi značajan problem mobilnih digitalnih komunikacija jest nepouzdanost i mala kvaliteta prijenosnog kanala, tj. velika vjerojatnost pogreški u prijenosu, kao i povremeni totalni prekidi kanala. Radi toga, predloženi standardi su morali biti imuni na takove probleme u prijenosu. Nažalost, umjesto jednog svjetskog standarda, razvijena su tri najznačajnija sustava mobilne digitalne telefonije: sjeverno američki standard IS54 VSELP standardiziran 1989 od tijela TIA (Telecommunication Industry Association), japanski standard JDC-VSELP standardiziran od strane RCR (Research and Development Center for Radio Systems) pod oznakom RCR STD-27B i europski standard GSM temeljen na RPE‑LTP koderu standardiziranom 1987 od strane Groupe Special Mobile of CEPT. Svi ti sustavi su već bili posebno prilagođeni govornom signalu, tj. visoka učinkovitost sažimanja ostvarena je upravo na račun činjenice da govorni signal u sebi sadrži popriličnu količinu redundantne informacije. Ako se 'bitna' informacija razdvoji od 'nebitne', te ako se 'nebitni' dio opiše modelom, a 'bitni' kvantizira, kodira i prenese na prijemnu stranu, moguće je ostvariti istu kvalitetu reprodukcije uz mnogo manju brzinu prijenosa digitalne informacije. Potrebna brzina prijenosa tih sustava jest: 7.95 kbit/s za IS54 i 13 kbit/s za GSM, dok je kvaliteta samo neznatno niža od one ostvarive klasičnim PCM i ADPCM sustavima.
2.1.3 Moderni koderi za primjene u mobilnim komunikacijama
Dodatni razvoj u području učinkovitog kodiranja govornog signala početkom 90-tih godina, rezultirao je razvojem niza novih standarda, kojima se uz očuvanje iste kvalitete, potrebna brzina prijenosa smanjuje s faktorom dva, ili se pak uz istu brzinu prijenosa ostvaruje veća kvaliteta. Ti su koderi poznati pod nazivima "Half-rate" odnosno "Enhanced full rate" koderi. Tako je 1994 predložena zamjena originalnog GSM kodera sa half-rate GSM standardom oznake ETSI-TCH-HS i brzine prijenosa od 5.6kbit/s. Isto tako originalni IS54 standard zamijenjen je s novim sjeverno-američkim standardnom IS96 QCELP u okviru novog standarda mobilne telefonije temeljene na CDMA pristupu (Code Division Multiple Access). Za razliku od originalnog VSELP kodera, novi QCELP koder ima skokovito promjenljivu brzinu prijenosa (0.8, 2, 4 ili 8.5 kbit/s) zavisno o sadržaju signala koji se kodira (govor ili pauza). Taj standard međutim nije u potpunosti ispunio očekivanja, pogotovo kada je u ulaznom govornom signalu bila prisutna značajna količina pozadinskog šuma. Za novi japanski standard JDC Half-Rate odabran je PSI-CELP koder brzine prijenosa od 3.45 kbit/s i kvalitete usporedive s full-rate standardom. Treba napomenuti da je dodatna učinkovitost sažimanja ostvarena na račun značajnog povećanja kompleksnosti kodiranja.
U okviru ITU-T organizacije, predložen je također čitav niz novih kodera. Tako je u svrhu zamjene zastarjelih PCM i ADPCM standarda, 1992 i 1994 predložen novi standard G.728 brzine prijenosa 16kbit/s temeljen na LD-CELP koderu malog kašnjenja. Isto tako, kao novi standard za mobilnu komunikaciju, je 1996 godine predložen standard G.729 temeljen na CS-ACELP koderu brizne prijenosa od 8 kbit/s. Kao dio standardizacije video-telefona, koji pored govora prenašaju i sliku, 1995 je predložen novi standard za kodiranje govora oznake G.723 koji ima varijabilnu brzinu prijenosa (5.3 ili 6.3 kbit/s zavisno o signalu). Kod svih do sada spomenutih kodera, frekvencijski pojas govornog signala koji je bio kodiran i prenašan na prijemnu stranu jest približno od 200Hz do 3.2kHz. Taj pojas je od presudnog značaja za razumljivost govorne poruke, no kvaliteta signala je ipak značajno narušena tako uskim frekvencijskim pojasom. Radi toga, drugi trend u standardizaciji novih kodera ide u smjeru povećanja kvalitete proširenjem pojasa. Ti koderi su poznati pod nazivom "Wide-band" koderi. Tako je ITU-T predložio nov standard oznake G.722 kod kojeg je pojas signala proširen na 50Hz – 7 kHz.
Još jedan sustav temeljen na digitalnom kodiranju govora je sustav satelitskih komunikacija za vezu s brodovima na pučini Inmarsat-M (International Maritime Satellite Corporation). Za potrebe tog sustava 1990 predložen je koder IMBE tipa potrebne brzine prijenosa od samo 4.15 kbit/s. Za razliku od većine prije spomenutih kodera koji su temeljeni na CELP shemi (Code Excited Linear Predictor), IMBE koder je temeljen na sinusoidalnoj reprezentaciji govornog signala.
2.1.4 Vojna primjena kodera govornog signala
Razvoj svih ovih sustava i novih kodera vjerojatno ne bi bio toliko brz, da u pozadini civilne primjene digitalnih govornih komunikacija nije bio i vojni aspekt, kao jedan od glavnih izvora financiranja većine navedenih razvojnih projekata. Američka vlada i ministarstvo obrane još je vrlo davno prepoznalo velik značaj digitalne reprezentacije govornog signala, što pored pojednostavljenja njegovog prijenosa omogućava i njegovo šifriranje u svrhu zaštite informacije. Tako je već 1970 započet rad na standardizaciji kodera oznake FS1015 koji je bio temeljen na klasičnoj "LPC Vocoder" shemi, brzine prijenosa od 2.4 kbit/s. Ovaj koder poznat je i pod oznakom LPC-10. Standardiziran je konačno 1984 od strane DoD (Department of Defense) i kasnije NATO-a. Treba svakako napomenuti, da za razliku od prije opisivanih kodera kod kojih se nastojala manje ili više doseći kvaliteta klasičnih analognih telefonskih veza, kod ovog kodera jedina težnja je bila na razumljivosti. Radi toga reproducirani govorni signal je poprilično neprirodan (zvuči sintetički). Brzina prijenosa od 2.4 kbit/s bila je određena brzinom tadašnjih modem uređaja korištenih za prijenos digitalne informacije. Razvojem novih modema koji su radili na brzini od 4.8 kbit/s, javila se potreba za novim standardom kod kojeg bi se riješio navedeni problem male kvalitete originalnog kodera. Tako je 1991 predložen novi standard FS1016 temeljen na CELP koderu brzine prijenosa od 4.8 kbit/s. Po kvaliteti. ovaj koder je i dalje nešto lošiji od GSM ili IS54 kodera, ali ima značajno nižu brzinu prijenosa, pogotovo u usporedbi sa GSM koderom.
Sredinom devedesetih, odlučeno je da se predloži novi standard za brzine prijenosa od 2.4kbit/s koji bi trebao u potpunosti zamijeniti FS1015 i FS1016. Kao cilj, traženo je da novi standard ima kvalitetu barem jednaku onoj ostvarivoj s FS1016 koderom koji radi na 4.8 kbit/s, a sa posebnim naglaskom na robusnost na pogreške u prijenosu i pozadinsku buku koja u vojnim primjenama može biti vrlo značajna (oklopno vozilo, tenk, lovački avion itd.). Kao novi standard odabran je koder MELP tipa.
2.1.5 Današnji trendovi u području kodiranja govora
I pored činjenice što se kod današnjih kodera faktori sažimanja približavaju teoretskom maksimumu, i dalje su istraživanja u ovom području vrlo intenzivna. Jedan od važnih aspekta kod stvarne primjene govornih tehnologija jest i složenost algoritma, tj. problem vezan uz potrebnu procesnu moć procesora na kojem će se provoditi dotične obrade. Taj problem je direktno vezan i s problemom utroška električke energije, jer je ta proporcionalna potrebnoj procesnoj moći. Radi toga, kod baterijski napajanih prijenosnih uređaja, kod kojih je problem potrošnje također vrlo značajan, velika pažnja se posvećuje projektiranju učinkovitih algoritama kodiranja govora, koji osiguravaju pogodan kompromis između sažimanja i složenosti.
Razvoj algoritama za kodiranje govora se i dalje nastavlja, a dodatno je potaknut i potrebom za konačnom definicijom i implementacijom novog standarda, koji bi služio kao osnova za mobilne sustave tzv. treće generacije.
2.1.6 Usporedba kvalitete poznatijih kodera govornog signala
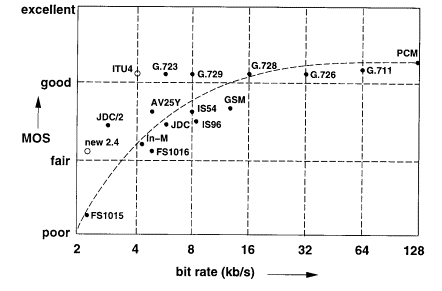
Na slici 2.1‑1 su prikazani usporedni rezultati testiranja subjektivne kvalitete svih navedenih kodera u idealnim uvjetima (čisti govorni signal, bez pogreški u prijenosu). Kao mjerilo subjektivne kvalitete korištena je tzv. MOS mjera (Mean Opinion Score), koja ocjenjuje kvalitetu reproduciranog signala sa: "poor"-loše, "fair"-prihvatljivo, "good"-dobro, "excellent"-izvrsno. Na x-osi je označena potrebna brzina prijenosa u logaritamskom mjerilu.
2.2 Sustavi za telekonferencije i udaljeno učenje
Jednu specifičnu primjenu algoritama za kodiranje govora predstavljaju sustavi za telekonferencije kao i sustavi za udaljeno učenje (engl. teleconferencing and distance learning). U tu grupu možemo ubrojiti i sustave za prijenos govornog signala putem Internet‑a (engl. Voice over IP) u svrhu zamjene ili nadopune klasičnih telekomunikacijskih sustava. Ono što je zajedničko za sve gore navedene sustave je činjenica da se govorni signal pretvara u digitalni oblik primjenom postupka kodiranja govora, te se zatim ta digitalna informacija prebacuje kroz digitalnu mrežu koja može biti bilo ISDN mreža u slučaju klasičnih telekonferencijskih sustava, ili pak Internet ili ATM računalna mreža u slučaju korištenja suvremenijih telekonferencijskih sustava temeljenih na PC tehnologiji i računalnim mrežama. Postupci kodiranja govora i slike, te razmjene digitalne informacije kod takvih sustava su propisani standardima, što osigurava inter‑operabilnost, tj. primjenu raznolikih krajnjih uređaja proizvedenih od širokog spektra proizvođača, bilo da se radi o samostalnim uređajima ili pak programskim rješenjima temeljenim na osobnom računalu s pripadnom multimedijskom podrškom (kamera, zvučna kartica, ISDN codec, mrežni priključak itd.). Pojava osobnog računala iznimno visokih procesnih mogućnosti je takve sustave iz domene skupih i specijaliziranih uređaja prebacila u domenu svakodnevne upotrebe kako u uredima tako i u kući. Potrebna infrastruktura za ostvarenje telekonferencije ili učenja na daljinu je postala minimalna, te je kao takva postala dostupna običnim korisnicima ograničenog budžeta. Istraživanja u ovom području su vrlo intenzivna, jer pored samog tehničkog problema, potrebno je nastavne materijale prilagoditi takvom načinu predavanja, a pored toga vrlo je značajno metodiku nastave prilagoditi novom mediju.
2.3 Primjena digitalne obrade govora u sintezi i prepoznavanju govora
Druge dvije također vrlo važne grane područja digitalne obrade govora predstavljaju automatsko prepoznavanje govora i sinteza govora. Ta dva područja su vrlo vezana, jer im je osnovna namjena prirodan način komunikacije čovjeka i računala. Specifičnosti obje primjene biti će detaljno objašnjenje u nastavku.
2.3.1 Automatsko prepoznavanje govora i detekcija riječi
Namjena automatskog prepoznavanja govora jest da govornu poruku izrečenu od strane ljudskog govornika pretvori u tekstualni oblik. U nekim slučajevima, radi se o komandama koje računalo mora prepoznati i zavisno o komadni izvršiti određenu akciju. Te su komande najčešće izolirane riječi iz relativno malog skupa komandi (npr. 100 različitih riječi). U drugom slučaju, računalo mora zamijeniti tajnicu, tj. mora prepoznati i pohraniti riječi koje mu diktira korisnik. Ako su riječi izolirane prilikom diktata, tada se to svodi na problem prepoznavanja izoliranih riječi. U ovom slučaju je skup riječi mnogo širi nego kod komandi, pa je i složenost sustava za prepoznavanje veća. Najsloženiji problem prepoznavanja govora predstavlja prepoznavanja spojenog (prirodnog) govora s riječima iz praktički neograničenih rječnika. Jedan od velikih problema sustava za prepoznavanje jest i zavisnost o govorniku. Od određenih sustava se traži da budu neosjetljivi na govornika, tj. da za sve govornike rade jednako dobro, dok se drugi pak adaptiraju za svakog pojedinog govornika. Namjena adaptacije je podešavanje pohranjenih statističkih modela načinu izgovora dotičnog govornika. Svi takvi sustavi su direktno vezani uz jezik koji se koristi, jer univerzalni sustavi koji bi radili za bilo koji jezik nisu niti približno tako dobri kao oni koji su projektirani za svaki jezik nezavisno. Razlog leži u činjenici što se učinkovitost prepoznavanja postiže ugradnjom fonetičkih i lingvističkih pravila u sustav prepoznavanja, a koja su naravno različita za svaki jezik. I pored svih navedenih problema, današnji sustavi za engleski jezik trenirani za dotičnog korisnika mogu postići točnost prepoznavanja od 95% za prirodni (vezani) izgovor s riječima iz vrlo velikih rječnika. Slično kao i kod kodiranja, riječ je o vrlo složenim algoritmima, tako da su mogućnosti sustava za prepoznavanje ovisne o procesnim mogućnostima sklopovske platforme. Prilikom razvoja novih verzija procesora opće namjene iz Intel-ove porodice, projektanti imaju u vidu potrebe za visokom procesnom moći algoritama za prepoznavanje govora, tako da su određene sklopovske pod-jedinice novih procesora projektirane upravo sa specijalnom zadaćom učinkovite izvedbe takvih algoritama. Danas postoje već brojni komercijalni programi za prepoznavanja govora za PC osobna računala. Isto tako, sustavi za prepoznavanje govora se ugrađuju u velik broj krajnjih produkata. Tako npr. jedna od budućih masovnih primjena prepoznavanja govora su "pametni" mobilni telefoni koji prepoznaju govorne komande, čime se omogućava rad s telefonom bez ruku. Umjesto da se prilikom uspostavljanja veze ručno bira broj, dovoljno je reći ime osobe koju se naziva i telefon će automatski prepoznati o kome se radi te iz memorije pročitati unaprijed pohranjeni telefonski broj dotične osobe i nazvati ga. Ako taj broj još ne postoji u imeniku, biranje se može provesti izgovorom niza željenih znamenki telefonskog broja. Drugi primjer masovne primjene su "pametni" automobili, kod kojih se upravljanje i komunikacija s ugrađenom elektroničkom opremom također provodi korištenjem glasovnih komandi. Takva elektronička oprema može obuhvaćati klasičnu opremu kao što su FM radio, CD, kazetofon, klima-uređaj, grijanje, ventilacija, kao i raznovrsni električki podesivi sustavi (prozori, zrcala, sjedala, rasvjeta itd.). Pored takvih klasičnih sustava, u novije vrijeme se u aute ugrađuju sustavi automatske satelitske navigacije koji omogućavaju nalaženje puta do cilja, zatim sustavi telefonske / Internet veze koji auto pretvaraju u mobilni ured, kao i svi mogući sustavi elektronike za zabavu (TV, DVD, video igre itd.). Obzirom da upravljanje tako složenim sustavima zahtijeva i odvlači previše pažnje vozaču automobila, čija je ipak glavna zadaća sama vožnja, primjena postupaka upravljanja govorom je jedino smisleno rješenje.
Jedna specifična primjena sustava za automatsko prepoznavanje su sustavi za detekciju riječi. Od takvih sustava se ne traži kompletna transkripcija razgovora, već isključivo detekcija određenih ključnih riječi u razgovoru. Najznačajnija primjena takvih sustava je u praćenju velikog broja telefonskih linija u svrhu nadzora. Da bi se olakšao posao ljudskim operaterima, računalo simultano prati velik broj linija i "čeka" pojavu ključnih riječi na bilo kojoj od aktivnih linija. U slučaju da se takve riječi pojave, snimljeni razgovor na toj liniji se prosljeđuje ljudskom operateru na definitivnu provjeru sadržaja. U slučaju da se očekuje točno određena osoba u razgovoru, tada se takvi sustavi mogu kombinirati i s automatskim prepoznavanjem govornika, čime se može dodatno povećati vjerojatnost sigurne detekcije "interesantnog" razgovora. Takvi sustavi su danas vrlo značajni, jer klasični postupci praćenja u modernim komunikacijskim sustavima više nisu primjenjivi, prvenstveno zbog enormnog broja korisnika koji istovremeno koriste takve sustave. Sustavi za detekciju se uobičajeno projektiraju za relativno mali skup ključnih riječi, jer moraju istovremeno osigurati i vrlo veliku vjerojatnost detekcije pravih riječi, kao i vrlo malu vjerojatnost lažne aktivacije tokom razgovora.
2.3.2 Digitalna sinteza govora
Naravno da je u svrhu prirodne komunikacije s računalom nužan i drugi smjer, tj. računalo mora biti sposobno da bilo kakvu informaciju koju želi prenijeti korisniku može pretvoriti u govornu poruku. I ovo područje se vrlo intenzivno razvijalo zadnjih 20-30 godina, tako da je danas već u prilično zreloj fazi. Kod najnovijih sustava za sintezu govora, prirodnost izgovora je toliko dobra da je već vrlo teško razlučiti da li se radi o živoj osobi ili o računalu. Ulogu sustava za automatsku sintezu govora najlakše je usporediti s zadaćom spikera na TV ili radio stanici, koji napisani tekst mora pročitati na pravilni način, tj. korištenjem svih pravila izgovora, naglaska, intonacije itd. Važno je naglasiti da ljudski čitač prilikom čitanja provodi i interpretaciju teksta, tj. napisana poruka na papiru neće biti pročitana doslovce nego će pojedine oznake brojke ili kratice biti pretvorene u riječi. Tako npr. pisana poruka oblika: "Jučer, 29.10.01 u 13:22 izbio je požar u Petrinjskoj ul. br. 22", biti će izgovorena na slijedeći način: "Jučer, dvadeset devetog listopada dvije tisuće i prve godine u trinaest sati i dvadeset i dvije minute izbio je požar u Petrinjskoj ulici na kućnom broju dvadeset i dva". Usporedbom ove dvije verzije iste poruke, očito je koliko je složena zadaća automatskog sustava za sintezu. Programi za sintezu starijih generacija taj bi gore navedeni tekst izgovorili na slijedeći način: "Jučer zarez dvadeset i devet točka deset točka nula jedan točka u trinaest dvotočka dvadeset i dva izbio je požar u Petrinjskoj ul točka br točka dvadeset i dva". Naravno da bi takav način sinteze bio vrlo naporan za slušača, a ponekad bi čak i smisao poruke bio pogrešno prenesen. Interpretacija (razumijevanje smisla poruke) vrlo je važna i za intonaciju. Pravilna intonacija zahtijeva točno prepoznavanje strukture rečenice, tj. što je imenica, pridjev, prilog, glagol, gdje je početak, gdje kraj itd. Očito da je u tu svrhu fonetička i lingvistička pravila pojedinog jezika potrebno opisati na matematički egzaktan način, čime se omogućava implementacija takovih pravila u sustavima za sintezu i prepoznavanje. Zbog tih činjenica je u posljednje vrijeme značajno promijenjen pristup i u tim znanstvenim područjima, te se sve više pažnje posvećuje "računalnoj" fonetici i lingvistici. Sustavi za automatsku sintezu se danas susreću u nizu primjena, od komercijalnih programa za PC računala, pa sve do dječjih igračaka koje danas sve manje ili više nešto pričaju.
2.3.3 Sustavi za dijalog s računalom
Objedinjavanjem sustava za prepoznavanje i sustava za sintezu, te dodavanjem sustava za umjetnu inteligenciju i baze podataka, dobivaju se sustavi za dijalog, koji također postaju jako popularni u novije vrijeme. Krajnji cilj takvih sustava je da u potpunosti zamijene ljudskog operatera u raznovrsnim uslugama informacija, kao što su npr. informacije o redu vožnje ili letenja na kolodvorima ili aerodromima, informacije o tel. brojevima, ili bilo kakve usluge korisnicima koje se nude od tzv. 'call-centara' velikih firmi (npr. servis, održavanje itd.). Jedna od interesantnih primjena je informacijski pult, gdje bi turist u stranom gradu razgovorom s računalom koje se nalazi "na cesti" saznao bilo kakvu potrebnu informaciju (od smještaja, restorana, kulturnih i povijesnih znamenitosti, snalaženja po gradu itd.). Zadatke koje mora obaviti takav sustav za dijalog se mogu svrstati u slijedeće glavne cjeline:
· snimanje izgovorene rečenice ili upita korisnika
· automatsko prepoznavanje (transkripcija govorne poruke u tekstualni zapis)
· određivanje smisla snimljene rečenice i detekcija svih ključnih riječi i informacija
· provjera kompletnosti upita
· zahtjev za upotpunjenje nedostajućih informacija
· prema potrebi provodi se i verifikacija smisla upita sa konačnom potvrdom tipa DA/NE
· pretraživanje baze podataka i određivanje traženog odgovora
· konstrukcija rečenice s odgovorom
· sinteza odgovora u govornu poruku
· reprodukcija odgovora
Obavljanje određene transakcije najčešće zahtijeva višestruke prolaze kroz gore opisane korake, tako dugo dok se kroz dijalog ne prikupe sve potrebne informacije da bi računalo moglo dati suvisao odgovor. Iz gornje diskusije je vidljivo da se radi o vrlo složenim sustavima, čije se znanje i inteligencija formiraju postupcima "učenja ili treninga". U tu svrhu se koriste govorne baze sa uobičajenim razgovorima za konačnu primjenu. Tako npr. ako se radi o projektiranju sustava za automatske informacije o redu letenja aviona, tada se prilikom učenja sustava moraju koristiti snimke razgovora stvarnih korisnika i živih operatera upravo te tematike. Iz tih snimki se zatim određuje skup riječi korišten u konverzacijama, te se sustav za automatsko prepoznavanje trenira da korektno prepoznaje samo riječi iz tog skupa. Iako to djeluje malo neobično, u takvim usko tematski specijaliziranim razgovorima fond riječi je prilično mali (par tisuća ili manje). Iz svih prikupljenih transkripcija razgovora potrebno je odrediti i tipove upita upućene od različitih korisnika, jer se ista stvar može upitati na velik broj različitih načina. Objedinjavanjem svih tih podataka formiraju se statistički modeli koji se koriste za prepoznavanje svih elemenata dijaloga :
· osnovnih fonemskih grupa,
· riječi,
· i rečenica
Treniranje sustava, tj. određivanje parametara tih statističkih modela, provodi se direktno na osnovu podataka određenih iz govorne baze za učenje. Pri svemu tome treba voditi računa i o činjenici da jedan određeni postotak riječi i rečenica ipak neće biti obuhvaćen modelima. Sustav mora biti robustan na takve slučajeve i tražiti od korisnika da preformulira pitanje, ako se postavljeni upit ne uklapa niti u jedan postojeći model. Za kvalitetno treniranje sustava potrebna je velika količina snimljenog govornog materijala (stotine sati), jer su čak i tada neke rijetke riječi ili neuobičajeni tipovi upita nedovoljno zastupljeni za pouzdano učenje statističkih modela. U svrhu vrednovanja takvih automatskih sustava uobičajeno se koristi kvocijent prosječnog trajanja transakcije obavljene s živim operaterom u odnosu na trajanje transakcije obavljene s računalom. I kod najboljih sustava taj kvocijent je i dalje u korist živih operatera. Velik problem je i u tome što se korisnici ponašaju potpuno drugačije kada shvate da je s druge strane veze računalo, pa i baza razgovora s živim operaterima nije dobar reprezentant stvarnih dijaloga koji će se pojaviti u konverzaciji s računalom. Radi toga modeli se uobičajeno moraju ponovno trenirati sa stvarnim razgovorima snimljenim nakon prve primjene takvih sustava. Ipak, zbog male pouzdanosti, takvi sustavi se danas koriste u eksperimentalne svrhe, prvenstveno za primjene gdje konačni rezultat (odgovor sustava) ipak nije od presudne važnosti i neće uzrokovati značajnu štetu ili probleme korisniku u slučaju da odgovor nije ono što je on tražio. Druga mogućnost je da se u slučajevima kada nije moguće ostvariti konstruktivni dijalog korisnika s računalom, da se tada on prospoji na živog operatera.
U slučaju kada se sustavi za dijalog primjenjuju u informacijskim pultovima, tada se oni obično kombiniraju i s jednom dodatnom tehnologijom, a to je tzv. "agent". Smisao agenta je da pored audio komunikacije, postoji i vizualna komunikacija čovjeka i računala, tj. video kamera snima korisnika i interpretira njegove izraze lica, dok se na ekranu računala animira lik virtualne osobe "računala" s kojom se provodi komunikacija. Animacija takvog virtualnog lika mora biti u skladu sa sustavom za sintezu govora, tako da se dobije sinkronizirani audio-vizualni doživljaj koji u potpunosti odgovara stvarnom razgovoru. Pokazalo se da sa takvim pristupom olakšava i ubrzava razgovor, jer pored funkcionalnosti takav sustav je zabavan i lakše prihvatljiv za korisnika.
2.3.4 Prepoznavanje govornika
Jedno specifično područje digitalne obrade govora se bavi problemom automatskog prepoznavanja govornika. Tipične primjene su sustavi koji moraju na osnovu izgovora točno određene (ili pak bilo kakve) govorne sekvence automatski odrediti o kojem govorniku iz konačnog skupa govornika se radi. Za svakog potencijalnog kandidata iz tog konačnog skupa govornika izračunava se vjerojatnost da je snimljena govorna sekvenca izgovorena upravo od strane tog govornika. Sortiranjem takve liste vjerojatnosti dobivaju se najvjerojatniji kandidati za prepoznavanje. Sustav radi dobro, ako je vjerojatnost pravog govornika mnogo veća od vjerojatnosti bilo kojeg drugog krivog govornika iz te baze (tj. na toj listi). Nekad, zbog inherentne sličnosti glasa dva različita govornika takva diskriminacija nije moguća, nego se oba javljaju na vrhu liste kao najbolji potencijalni kandidati s vrlo bliskim vjerojatnostima prepoznavanja. U takvim slučajevima zamjene su moguće i neizbježne, jer su objektivno karakteri ta dva glasa vrlo slični. Razlikovanje između govornika treba prvenstveno temeljiti na onim parametrima koji su fizikalno uvjetovani, tj. koji su određeni biofizikalnim značajkama govornika (oblik i duljina vokalnog trakta), a ne na onim parametrima koji se mogu vježbom lažno učiniti sličnim originalnom govorniku (kao što to rade profesionalni imitatori). Također treba voditi računa o pouzdanoj negativnoj detekciji glasova govornika koji se ne nalaze u bazi autoriziranih korisnika. Svi takvi glasovi moraju biti klasificirani kao "nepoznati", tj. prilikom usporedbe tog glasa s glasovima autoriziranih kandidata u bazi, vjerojatnost svakog kandidata iz baze mora biti ispod traženog minimalnog praga potrebnog za detekciju autoriziranog govornika. Pouzdanost isključenja "nepoznatih" govornika može se osigurati na više načina:
· samo autorizirani korisnik poznaje rečenicu koju mora izgovoriti, i/ili
· ta rečenica (password) se mijenja prilikom svakog ulaza prema nekom unaprijed dogovorenom pravilu koje znaju samo autorizirani korisnici, i/ili
· radi jednostavnosti, traženu rečenicu računalo ispisuje na terminalu, te korisnik mora izgovoriti baš tu rečenicu, čime se eliminira mogućnost korištenja ilegalno unaprijed snimljene rečenice pravog govornika, ili pak uvježbavanje pravilne imitacije već korištenog password-a.
Slični mehanizmi se koriste i kod konvencionalnih autorizacija korištenjem login/password-a na računalu. Treba voditi računa i o činjenici da se glas istog govornika mijenja sa starenjem. Te su promjene vrlo izražene u djetinjstvu, kao i u starijoj dobi kada dolazi do značajnih promjena biofizikalnih parametara. Isto tako, do promjene glasa može doći uslijed bolest kao što su prehlade, upale grla itd. Sustavi za identifikaciju moraju biti projektirani tako da uzimaju u obzir i takve modifikacije glasa, jer se u protivnom statistički modeli moraju nanovo trenirati na novi glas. Osnovni principi koji se koriste kod prepoznavanja govornika su vrlo slični postupcima prepoznavanja govora i temeljeni su na neovisnim statističkim modelima za svakog govornika, čiji se parametri određuju postupcima treninga na osnovi višestrukih izgovora različitih sekvenci koje se koriste prilikom autorizacije. Najveća pouzdanost sustava se postiže ako su prilikom treniranja statističkih modela korištene iste rečenice koje će biti korištene i prilikom prepoznavanja. U slučaju da se prilikom autorizacije koristi proizvoljna govorna sekvenca, tada je problem automatskog prepoznavanja govornika mnogo složeniji.
Takvi sustavi se mogu koristiti kao jedan od modaliteta provjere identiteta prilikom ulaza u osiguranu zonu, kombinirajući ih sa drugim modalitetima identifikacije kao što su: unos šifre na tastaturi, identifikacija primjenom chip-kartice, otisak prsta, slika retine, digitalizirani potpis, itd. Maksimalna pouzdanost identifikacije postiže se isključivo kombinacijom odabranih ili svih navedenih modaliteta.
Druga popularna primjena sustava za automatsko prepoznavanje govornika jest u programima za automatsko prepoznavanje govora. Kao što je prije diskutirano, kvaliteta prepoznavanja govora se može značajno uvećati, ako se statistički modeli riječi ili fonetskih grupa adaptiraju (podese) na način izgovora upravo tog konkretnog korisnika. Radi toga, takvi programi za svakog potencijalnog korisnika vode konfiguracijsku datoteku u kojoj su pohranjeni parametri specifični za tog govornika. Na početku korištenja programa za automatsko prepoznavanje govora, potrebno je računalu dati do znanja o kojem korisniku se radi, da bi program koristio pripadajuću konfiguracijsku datoteku. Taj odabir govornika može biti proveden manualno (odabirom opcije u izborniku programa), ili pak što je mnogo atraktivnije automatski, tako da program samostalno prepozna o kojem govorniku se radi, te na osnovu toga odabere pripadne parametre za automatsko prepoznavanje govora.
Treća vrlo značajna primjena je u forenzičke svrhe, tj. kao dokaz identiteta u sudskim sporovima. Isto tako, kao što je već diskutirano u poglavlju o sustavima za detekciju riječi, automatsko prepoznavanje govornika se može koristiti u sustavima za praćenje razgovora u svrhu detekcije "interesantnog" materijala.
Zadnja primjena koju ćemo spomenuti je u sustavima za automatsku transkripciju govornih emisija ili snimljenih razgovora u kojima je sudjelovao veći broj govornika. U tom slučaju pored prepoznavanja govora, potrebno je odrediti koji dio teksta pripada pojedinom govorniku u tom snimljenom materijalu.
Valja napomenuti, da su sve navedene aplikacije vrlo zahtjevne i naporne ako ih moraju provoditi živi operateri, pa je stoga značaj automatskih sustava utoliko veći. Međutim, zbog konačnih mogućnosti i pouzdanosti takvih automatskih sustava, oni se često koriste samo kao alat, koji smanjuje količinu posla živom slušaču, dok se kritične odluke ipak moraju prepustiti ljudskom uhu.
2.3.5 Automatsko prepoznavanje jezika
Jedna od novijih primjena digitalne obrade govora je u sustavima za automatsko prepoznavanje jezika, na osnovu snimljene govorne sekvence nepoznatog sadržaja. Takvi sustavi se integriraju u sustave za automatski dijalog koji mogu provoditi razgovor s potencijalnim korisnikom na bilo kojem jeziku, tj. na materinjem jeziku tog korisnika. Obzirom da sustavi za dijalog izrazito ovise o korištenom jeziku i obzirom da su direktno projektirani i trenirani za svaki pojedini jezik, univerzalni sustav za dijalog se u biti sastoji od N paralelnih sustava od kojih je svaki projektiran za jedan specifični jezik. Da bi bilo moguće odabrati jedan od tih sustava potrebna je povratna veza od strane korisnika, koji na neki način mora sustavu dati do znanja koji jezik bi želio koristiti u dijalogu. Do sada se to obavljalo direktnim odabirom iz nekog izbornika, ili pak ako se radi o sustavu implementiranom na klasičnoj telefonskoj infrastrukturi, tada se odabir obavljao DTMF signalima, tj. biranjem na tastaturi telefona. Novi pristup detekciji jezika temeljen je na direktnom prepoznavanju jezika na osnovu glasa korisnika. U tom postupku se pokušavaju oponašati mogućnosti ljudskog slušača, koji je kadar prepoznati jezik govornika i bez da poznaje riječi dotičnog jezika. To znači da čovjek može i bez razumijevanja što govori dotični govornik, prepoznati da li se radi o ovom ili onom jeziku. Pri tome se koristimo značajkama kao što su:
· fonetske karakteristike jezika (glasovi koji se javljaju u govoru)
· melodičnost i način izgovora (intonacija)
Analogno sustavima za automatsko prepoznavanje govora i govornika, moguće je sa svaki jezik formirati statističke modele koji opisuju akustičke značajke govora na tom jeziku. Cilj je ostvariti sustave koji su u mogućnosti odrediti jezik sugovornika, na osnovu što kraće govorne sekvence. Brzina detekcije jezika je značajna jer je detekciju potrebno obaviti prije početka samog dijaloga.
Takvi sustavi detekcije jezika, koji su neovisni o samoj govornoj poruci, mogu se kombinirati sa rezultatima prepoznavanja govora da bi se povećala njihova učinkovitost. To se radi tako da se snimljena govorna poruka koja se koristi za detekciju jezika propusti kroz svih N sustava za prepoznavanje govora, tj. da se prepoznavanje govora provede uz hipotezu svakog od N potencijalnih jezika. Obzirom da se prilikom prepoznavanja dobivaju vjerojatnosti svake izgovorene riječi, odnosno rečenice, moguće je za svaku hipotezu jezika dobiti vjerojatnosti prepoznate govorne sekvence. Onaj jezik koji rezultira najvećom vjerojatnošću prepoznavanja govorne poruke jest vjerojatno stvarni jezik korišten od strane govornika.
2.4 Sustavi za transformacije govorne poruke
Jedno posebno područje digitalne obrade govora predstavlja primjena u sustavima za transformacije govorne poruke. Tipične transformacije govora mogu biti:
· promjena spola govornika (muško u ženski i obratno)
· promjena visine glasa
· promjena brzine izgovora (ubrzavanje ili usporavanje)
· poboljšanje kvalitete govora (npr. uklanjanje signala smetnje ili šuma)
U nastavku će biti ukratko opisane tipične primjene takvih sustava. Prva primjena je kod ronioca s bocama za disanje. U slučaju kada se roni na većim dubinama, tada se pored komprimiranog zraka u bocama nalazi i plin helij, koji sprječava komplikacije koje mogu nastupiti pri ronjenju uz veliki tlak. Međutim, helij značajno mijenja akustička svojstva medija (fluida) u vokalnom traktu, što uzrokuje velike promjene u glasu (glas postaje visok, ... nešto kao Pajo patak). Da bi se olakšala komunikacija ronioca moguće je uz primjenu sustava za transformaciju govora vratiti govor u normalni oblik.
Drugi primjer primjene je kod pilota lovačkih aviona, koji također dišu zrak pod pritiskom i koriste specijalna "aktivna" odjela koja vanjskim pritiskom kompenziraju povišeni tlak u plućima. Pritisak zraka i pritisak odijela se dinamički mijenja zavisno o trenutnim akceleracijama u avionu, da spriječi bježanje krvi iz glave u noge. Uslijed povišenog tlaka, mijenja se oblik vokalnog trakta, te producirani govor nema iste značajke kao i govor u normalnim uvjetima. I u ovom slučaju je moguće određenim transformacijama, vratiti takav izobličeni govor u prirodni oblik, te poboljšati kvalitetu komunikacije.
Interesantne primjene su u sustavima za promjenu identiteta govornika, gdje je moguće zadržati sadržaj i brzinu izgovora govorne poruke, a kompletno promijeniti karakter glasa govornika. Takvi sustavi se koriste npr. prilikom svjedočenja zaštićenih svjedoka u sudskim sporovima, ili pak u raznim primjenama kod kojih se iz sigurnosnih razloga mora zaštiti pravi identitet govornika. Još jedna primjena takvih sustava je u zabavnoj industriji, kao npr. modifikacija glasa animiranog lika u crtanim filmovima, ili pak raznovrsne modifikacije glasa pjevača u muzičkoj produkciji.
U određenim slučajevima poželjno je zadržati istu boju glasa, ali se želi unaprijed snimljenu govornu poruku reproducirati većom ili manjom brzinom od stvarne. Veća brzina reprodukcije pogodna je kod pretraživanja većih govornih baza u svrhu nalaženja interesantnog materijala. Kod jeftinijih sustava reprodukcije audio‑vizualnog zapisa (kao što su npr. klasični video‑rekorderi), kod kojih ne postoje sustavi za transformaciju brzine reprodukcije audio zapisa, prilikom ubrzane reprodukcije se uobičajeno audio zapis ne reproducira, već isključivo samo slika. Ugradnjom takovog sustava za ubrzanu / usporenu reprodukciju govornog ili audio signala, moguće je ostvariti reprodukciju kompletnog audio‑vizualnog zapisa u svim brzinama reprodukcije.
Zadnja grupa sustava za transformaciju govora su sustavi za poboljšanje kvalitete govora. Kvaliteta i razumljivost govora mogu biti ugroženi različitim izvorima smetnji ili izobličenja. Tipični izvori su:
· kvantizacijski šum uzrokovan kodiranjem govora
· okolni šum (buka) pribrojen govornom signalu kao smetnja
· drugi govornik ili govornici koji govore u pozadini
· revebracije (jeke) koje se javljaju prilikom snimanja u zatvorenim prostorijama s lošim akustičkim svojstvima
· jeke uzrokovane preslušavanjima u raznim točkama prijenosnog kanala
· pojava mikrofonije (akustičke povratne veze) prilikom snimanja u prostorijama u kojima se signal s mikrofona reproducira na sustavu ozvučenja
Način otklanjanja svakog od navedenih izvora smetnji je specifičan za svaki od navedenih sustava, a provodi se specifičnim uređajima kao što su:
· uređaj za poništenje akustičke povratne veze (engl. acoustic feedback canceller)
· uređaj za poništenje jeke (engl. echo canceller)
· uređaj za povećanje kvalitete govora (engl. speech enhancement device)
Postupci i uređaju koji se primjenjuju za jedan dio gore navedenih transformacija su univerzalni za sve tipove audio signala, tj. nisu projektirani specifično za govor, dok je drugi dio učinkovit jedino u slučaju kada se primjenjuje na govorni signal.
2.5 Sustavi za pomoć ljudima s tjelesnim oštećenjima
Digitalna obrada govora primjenjuje se i u raznovrsnim sustavima za pomoć ljudima s tjelesnim oštećenjima. Tako npr. ljudi koji su nijemi mogu koristiti prijenosne uređaje za sintezu govora, kod kojih se željena poruka odabire i formira primjenom namjenske tipkovnice, te sintetizira i reproducira primjenom takvih uređaja. Kod osoba koje su gluhe, mogu se primjenjivati sustavi za automatsko prepoznavanje govora, koji prihvaćenu govornu poruku mogu prepoznati i prikazati u tekstualnom obliku na zaslonu prijenosnog uređaja.
Postoji velik problem u učenju govora kod osoba koje su gluhe od rođenja. U takvim slučajevima, potreban je vrlo veliki trud specijaliziranog osoblja koje radi s djecom, da se i pored činjenice da dijete ne čuje svoj vlastiti izgovor postigne zadovoljavajuća kvaliteta govora. U tu svrhu se danas koriste programi koji provode analizu izgovora, te vizualnim putem daju direktnu povratnu vezu govorniku kako poboljšati izgovor. Na ovaj način, svaka osoba može raditi sama i bez direktne pomoći specijaliziranog osoblja za obuku. Ovakvi programi su prilagođeni uzrastu korisnika, tako da učenje čine interesantnim i zabavnim, jer više liče na igru nego na program za učenje.
Kod slijepih osoba, sva vizualna komunikacija se mora obaviti zvučnim ili taktilnim putem. Da se takvim osobama omogući čitanje normalnih knjiga ili tiska, tekst u grafičkom obliku se skenira (digitalizira), te prevodi u tekstualni zapis primjenom programa za automatsko prepoznavanje teksta (engl. optical character recognition). Takav tekst se tada može reproducirati primjenom sustava za sintezu govora, čime se zapravo ostvaruje postupak automatskog čitanja otisnutog teksta.
Digitalna obrada govora se primjenjuje i u tzv. umjetnim pužnicama, tj. kod osoba koje su oštećenog sluha, ali im je živčani dio slušnog sustava zdrav i upotrebljiv. Naziv umjetna pužnica i nije najprimjereniji, jer se u stvari radi o direktnoj električkoj stimulaciji živčanih završetaka u prirodnoj pužnici primjenom specijalne elektrode s velikim broj izvoda koji stimuliraju živce duž cijele pužnice. Takvom električkom stimulacijom se može zamijeniti uloga uha kod kojeg se stimulacija tih živaca provodi akustičkim putem pomicanjem vrlo malih dlačica koje se nalaze unutar pužnice. Sustav za električku pobudu stimulatora je minijaturan i često odvojen od glavnog dijela sustava u kojem se provodi pretvorba govornog signala snimljenog mikrofonom u niz impulsa određenih amplituda i frekvencija koji se prosljeđuju do pojedinih izvoda elektrode. Danas je operativni zahvat ugradnje umjetne pužnice vrlo rasprostranjen u svijetu i brojnim osobama je primjenom takvih uređaja vraćen sluh.
Digitalna obrada govora se koristi i u sustavima za dijagnostiku raznovrsnih poremećaja sluha ili govora. Pri tome je primjenom određenih postupaka moguće točno odrediti mjesto i tip oboljenja, te pratiti razvoj bolesti, odnosno terapijski tijek.
2.6 Zaključak
Kroz ova uvodna poglavlja željelo se ilustrirati koliko je široko područje digitalne obrade govora i koliko su brojne primjene u kojima se primjenjuju postupci digitalne obrade. Jednako tako su široke i profesije u kojima su nužna znanja iz digitalne obrade govora, kao što su telekomunikacije (žične i bežične), digitalni radio i televizija, multimedijski sustavi, telekonferencijski sustavi i učenje na daljinu, sudstvo, forenzika, informacijske i obavještajne službe (tajne i javne), vojna primjena, primjena u medicini i defektologiji, itd. Zbog složenosti ukupne problematike, poznavanje svih opisanih primjena je praktički nemoguće, tako da će se istraživači u pravilu profilirati u jednom ili više relativno uskih područja obrade govora zavisno o vlastitim interesima i željama.
2.7 Potrebna znanja za digitalnu obradu govora
U svrhu lakšeg savladavanja gradiva predmeta digitalne obrade signala nužna su određena predznanja. Najbitnija znanja su iz područja signala i sustava, te digitalne obrade signala, tj. vremenski diskretnih sustava. Ta znanja obuhvaćaju osnovne pojmove iz modeliranja linearnih vremenski nepromjenjivih sustava, kao i pripadne transformacije signala i sustava. U slučaju kontinuiranih sustava tu se misli na reprezentaciju sustava korištenjem linearnih diferencijalnih jednadžbi u vremenskoj domeni, odnosno reprezentaciju signala i sustava u frekvencijskoj domeni primjenom Laplace‑ove transformacije. U slučaju vremenski diskretnih signala i sustava, radi se o modeliranju pomoću jednadžbi diferencija, odnosno ekvivalentni modeli u frekvencijskoj domeni temeljeni na Z transformaciji. Specijalni slučaj Laplace‑ove i Z transformacije su Fourier-ova transformacija, odnosno vremenski diskretna Fourier-ova transformacija koje opisuju frekvencijske karakteristike takvih sustava i signala u stacionarnom stanju. U okviru gradiva biti će opisivan akustički model vokalnog trakta temeljen na spojenim cijevima bez gubitaka. Takav model ima električki dual, koji je temeljeni na propagaciji signala duž električnih linija bez gubitaka. Radi toga, kompletna teorija koja se koristi u modeliranju i analizi električnih linija je direktno primjenjiva i u ovom području. Osnova znanja iz filtracije u vremenski diskretnoj domeni primjenom rekurzivnih i nerekurzivnih filtara su također vrlo značaja, jer su glavni digitalni modeli vokalnog trakta temeljeni na upravo takvim filtrima. Obzirom da će govorni signal biti modeliran i analiziran u obje domene (kontinuiranoj i vremenski diskretnoj), bitno je poznavati osnove postavke otipkavanja i rekonstrukcije signala.
Za primjene u automatskom prepoznavanju govora, govornika, jezika ili detekciji riječi, pored ovih osnovnih znanja koja su prvenstveno iz domene obrade signala, potreba su i znanja iz slučajnih procesa i sustava, te modeliranja takvih stohastičkih sustava. Jedan od glavnih alata u tom modeliranju su skriveni Markovljevi modeli (engl. Hidden Markov Model) temeljeni na diskretnim ili kontinuiranim opservacijama.
Područje digitalne obrade govora je posebno interesantno upravo zbog činjenice da kombinira praktične aspekte digitalne obrade signala sa matematičkim znanjima iz područja modeliranja slučajnih procesa i sustava. Ono što posebno stimulira istraživače u tom području je i činjenica što sva ta teorija ima i vrlo realnu primjenu u svakodnevnom životu.